

 Android & iPhone
Android & iPhone生于边缘:去中心化算力网络如何赋能Crypto与AI?

YoubiCapitai
刚刚
作者:Jane Doe, Chen Li,通讯作者:Youbi投资团队
1 AI与Crypto的交点
5月23日,芯片巨头英伟达发布了2025财年第一季度财报。财报显示,英伟达第一季度营收为260亿美元。其中,数据中心营收较去年增长427%,达到惊人的226亿美元。英伟达能够凭借一己之力拯救美股大盘的财务表现背后,反映的是全球科技公司为了角逐AI赛道而爆发的算力需求。越是顶尖的科技公司在AI赛道布局的野心越大,相应的,这些公司对于算力的需求也呈指数级增长。根据TrendForce的预测,2024年美国四大主要云服务提供商:微软、谷歌、AWS和Meta的对于高端AI服务器的需求预计分别将占全球需求的20.2%、16.6%、16%和10.8%,总计超60%。

图片来源: https://investor.nvidia.com/financial-info/financial-reports/default.aspx
“芯片紧缺“连续成为近几年的年度热词。一方面,大语言模型(LLM)的training和inference需要大量算力支撑;并且随着模型的迭代,算力成本和需求呈指数级增加。另一方面,像Meta这样的大公司会采购巨量的芯片,全球的算力资源都向这些科技巨头倾斜,使得小型企业越来越难以获得所需的算力资源。小型企业面临的困境不仅来自于激增的需求导致的芯片供给不足,还来自于供给的结构性矛盾。目前,在供给端仍存在着大量闲置的GPU,比如,一些数据中心存在大量闲置的算力(使用率仅在12% – 18%),加密挖矿中由于利润的减少也闲置出来大量的算力资源。虽然这些算力并非都适合AI训练等专业的应用场景,但消费级硬件在其他领域,如AI inference、云游戏渲染、云手机等领域仍然可以发挥巨大作用。整合并利用这部分算力资源的机会是巨大的。
把视线从AI转到crypto,在加密市场沉寂了三年之后,终于又迎来了又一轮牛市,比特币价格屡创新高,各种memecoin层出不穷。虽然AI和Crypto作为buzzword火了这些年,但人工智能和区块链作为两项重要技术仿佛两条平行线,迟迟没有找到一个“交点”。今年年初,Vitalik发表了一篇名为“The promise and challenges of crypto + AI applications” 的文章,讨论了未来AI和crypto相结合的场景。Vitalik在文中提到了很多的畅想,包括利用区块链和MPC等加密技术对AI进行去中心化的training和inference,可以将machine learning的黑箱打开,从而让AI model更加trustless等等。这些愿景若要实现还有很长一段路要走。但其中Vitalik提到的其中一个用例——利用crypto的经济激励来赋能AI,也是一个重要且在短时间内可以实现的一个方向。去中心化算力网络便是现阶段AI + crypto最合适的场景之一。
2 去中心化算力网络
目前,已经有不少项目在去中心化算力网络的赛道上发展。这些项目的底层逻辑是相似的,可以概括为: 利用token激励算力持有者参与网络提供算力服务,这些零散的算力资源可以汇集成有一定规模的去中心化算力网络。这样既能提高闲置算力的利用率,又能以更低的成本满足客户的算力需求,实现买方卖方双方的共赢。
为了使读者在短时间内获得对此赛道的整体把握,本文将从微观—宏观两个视角对具体的项目和整个赛道进行解构,旨在为读者提供分析视角去理解每个项目的核心竞争优势以及去中心化算力赛道整体的发展情况。笔者将介绍并分析五个项目: Aethir、io.net、Render Network、Akash Network、Gensyn,并对项目情况和赛道发展进行总结和评价。
从分析框架而言,如果聚焦于一个具体的去中心化算力网络,我们可以将其拆解成四个核心的构成部分:
硬件网络:将分散的算力资源整合在一起,通过分布在全球各地的节点来实现算力资源的共享和负载均衡,是去中心化算力网络的基础层。
双边市场:通过合理的定价机制和发现机制将算力提供者与需求者进行匹配,提供安全的交易平台,确保供需双方的交易透明、公平和可信。
共识机制:用于确保网络内节点正确运行并完成工作。共识机制主要用于监测两个层面:1)监测节点是否在线运行,处于可以随时接受任务的活跃状态;2)节点工作证明:该节点接到任务后有效正确地完成了任务,算力没有被用于其他目的而占用了进程和线程。
代币激励:代币模型用于激励更多的参与方提供/使用服务,并且用token捕获这种网络效应,实现社区收益共享。
如果鸟瞰整个去中心化算力赛道,Blockworks Research的研报提供了一个很好的分析框架,我们可以将此赛道的项目position分为三个不同的layer。
Bare metal layer: 构成去中心化计算栈的基础层,主要的任务是收集原始算力资源并且让它们能够被API调用。
Orchestration layer: 构成去中心化计算栈的中间层,主要的任务是协调和抽象,负责算力的调度、扩展、操作、负载均衡和容错等。主要作用是“抽象”底层硬件管理的复杂性,为终端用户提供一个更加高级的用户界面,服务特定的客群。
Aggregation layer: 构成去中心化计算栈的顶层,主要的任务是整合,负责提供一个统一的界面让用户可以在一处实现多种计算任务,比如AI训练、渲染、zkML等等。相当于多个去中心化计算服务的编排和分发层。
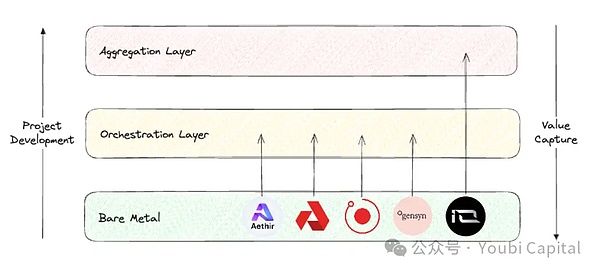
图片来源:Youbi Capital
根据以上两个分析框架,我们将对选取的五个项目做一个横向的对比,并从四个层面——核心业务、市场定位、硬件设施和财务表现对其进行评价。
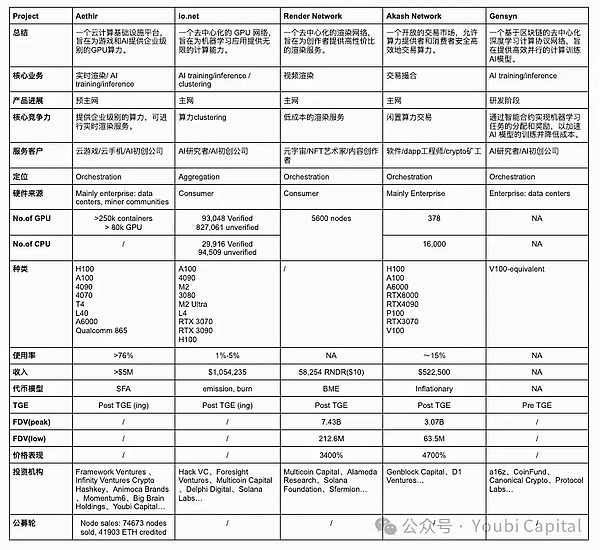
2.1 核心业务
从底层逻辑来讲,去中心化算力网络是高度同质化的,即利用token激励闲置算力持有者提供算力服务。围绕这个底层逻辑,我们可以从三个方面的差异来理解项目核心业务的不同:
闲置算力的来源:
市面上闲置算力有两种主要的来源:1)data centers, 矿商等企业手里闲置算力;2)散户手里的闲置算力。数据中心的算力通常是专业级别的硬件,而散户通常会购买消费级别的芯片。
Aethir、Akash Network和Gensyn的算力主要是从企业收集的。从企业收集算力的好处在于:1)企业和数据中心通常拥有更高质量的硬件和专业维护团队,算力资源的性能和可靠性更高;2)企业和数据中心的算力资源往往更同质化,并且集中的管理和监控使得资源的调度和维护更加高效。但相应的,这种方式对于项目方的要求较高,需要项目方有与掌握算力的企业有商业联系。同时,可扩展性和去中心化程度会受到一定程度的影响。
Render Network和io.net主要是激励散户提供手中的闲置算力。从散户手中收集算力的好处在于:1)散户的闲置算力显性成本较低,能提供更加经济的算力资源;2)网络的可扩展性和去中心化程度更高,增强了系统的弹性和稳健性。而缺点在于,散户资源分布广泛且不统一,管理和调度变得复杂,增加了运维难度。并且依靠散户算力去形成初步的网络效应会更加困难(更难kickstart)。最后,散户的设备可能存在更多的安全隐患,会带来数据泄露和算力被滥用的风险。
算力消费者
从算力消费者来讲,Aethir、io.net、Gensyn的目标客户主要是企业。对于B端客户来说,AI和游戏实时渲染需要高性能计算需求。这类工作负载对算力资源的要求极高,通常需要高端 GPU 或专业级硬件。此外,B端客户对算力资源的稳定性和可靠性要求很高,因此必须提供高质量的服务级别协议,确保项目正常运行并提供及时的技术支持。同时,B端客户的迁移成本很高,如果去中心化网络没有成熟的SDK能够让项目方快速deploy(比如Akash Network需要用户自己基于远程端口进行开发),那么很难让客户进行迁移。如果不是及其显著的价格优势,客户迁移的意愿是非常低的。
Render Network和Akash Network主要为散户提供算力服务。为C端用户提供服务,项目需要设计简单易用的界面和工具,为消费者提供良好的消费体验。并且消费者对于对价格很敏感,因此项目需要提供有竞争力的定价。
硬件类型
常见的计算硬件资源包括CPU、FPGA、GPU、ASIC和SoC等。这些硬件在设计目标、性能特性和应用领域上有显著区别。总结来说,CPU更擅长通用计算任务,FPGA的优势在于高并行处理和可编程性,GPU在并行计算中表现出色,ASIC在特定任务中效率最高,而SoC则集成多种功能于一体,适用于高度集成的应用。选择哪种硬件取决于具体应用的需求、性能要求和成本考虑。我们讨论的去中心化算力项目多为收集GPU算力,这是由项目业务类型和GPU的特点决定的。因为GPU在AI训练、并行计算、多媒体渲染等方面有着独特优势。
虽然这些项目大多涉及到GPU的集成,但是不同的应用对硬件规格的要求不同,因此这些硬件有异质化的优化核心和参数。这些参数包括parallelism/serial dependencies,内存,延迟等等。例如渲染工作负载实际上更适合于消费级 GPU,而不适合性能更强的data center GPU,因为渲染对于光线追踪等要求高,消费级芯片如4090s等强化了RT cores,专门为光线追踪任务做了计算类优化。AI training和inference则需要专业级别的GPU。因此Render Network 可从散户那里汇集 RTX 3090s 和 4090s等消费级GPU,而IO.NET需要更多的H100s、 A100s等专业级别GPU,以满足AI初创公司的需求。
2.2 市场定位
对于项目的定位来讲,bare metal layer、orchestration layer和aggregation layer需要解决的核心问题、优化重点和价值捕获的能力不同。
Bare metal layer 关注的是物理资源的收集和利用,Orchestration layer 关注算力的调度和优化,将物理硬件按照客户群体的需求进行最佳优化设计。Aggregation layer是general purpose的,关注不同资源的整合和抽象。从价值链来讲,各个项目应该从bare metal层起,努力向上进行攀升。
从价值捕获的角度来讲,从bare metal layer、orchestration layer 到aggregation layer,价值捕获的能力是逐层递增的。Aggregation layer能够捕获最多的价值,原因在于aggregation platform能够获得最大的网络效应,还能直接触及最多的用户,相当于去中心化网络的流量入口,从而在整个算力资源管理栈中占据最高的价值捕获位置。
相应的,想要构建一个aggregation platform的难度也是最大的,项目需要综合解决技术复杂性、异构资源管理、系统可靠性和可扩展性、网络效应实现、安全性和隐私保护以及复杂的运维管理等多方面的问题。这些挑战不利于项目的冷启动,并且取决于赛道的发展情况和时机。在orchestration layer还未发展成熟吃下一定市场份额时,做aggregation layer是不太现实的。
目前,Aethir、Render Network、Akash Network和Gensyn都属于Orchestration layer,他们旨在为特定的目标和客户群体提供服务。Aethir目前的主营业务是为云游戏做实时渲染,并为B端客户提供一定的开发和部署环境和工具; Render Network主营业务是视频渲染,Akash Network的任务是提供一个类似于淘宝的交易平台,而Gensyn深耕于AI training领域。io.net的定位是Aggregation layer,但目前io实现的功能还离aggregation layer的完整功能还有一段距离,虽然已经收集了Render Network和Filecoin的硬件,但对于硬件资源的抽象和整合还未完成。
2.3 硬件设施
目前,不是所有项目都公布了网络的详细数据,相对来说,io.net explorer的UI做的是最好的,上面可以看到GPU/CPU数量、种类、价格、分布、网络用量、节点收入等等参数。但是4月末时io.net的前端遭到了攻击,由于io没有对 PUT/POST 的接口做 Auth,黑客篡改了前端数据。这为其他项目的隐私、网络数据可靠性也敲响了警钟。
从GPU的数量和model来说,作为聚合层的io.net收集的硬件数量理应是最多的。Aethir紧随其后,其他项目的硬件情况没有那么透明。从GPU model上可以看到,io既有A100这样的专业级GPU,也有4090这样的消费级GPU,种类繁多,这符合io.net aggregation的定位。io可以根据具体任务需求选择最合适的GPU。但不同型号和品牌的GPU可能需要不同的驱动和配置,软件也需要进行复杂的优化,这增加了管理和维护的复杂性。目前io各类任务分配主要是靠用户自主选择。
Aethir发布了自己的矿机,五月时,高通支持研发的Aethir Edge正式推出。它将打破远离用户的单一集中化的GPU集群部署方式,将算力部署到边缘。Aethir Edge将结合H100的集群算力,共同为AI场景服务,它可以部署训练好的模型,以最优的成本为用户提供推理计算服务。这种方案离用户更近,服务更快速,性价比也更高。
从供给和需求来看,以Akash Network为例,其统计数据显示,CPU总量约为16k,GPU数量为378个,按照网络租赁需求,CPU和GPU的利用率分别是11.1%和19.3%。其中只有专业级GPU H100的租用率是比较高的,其他的model大多处于闲置状态。其他网络面临的情况大体与Akash一致,网络总体需求量不高,除了如A100、H100等热门芯片,其他算力大多处于闲置的状态。
从价格优势来看,与除云计算市场巨头而言,与其他传统服务商相比成本优势并不突出。
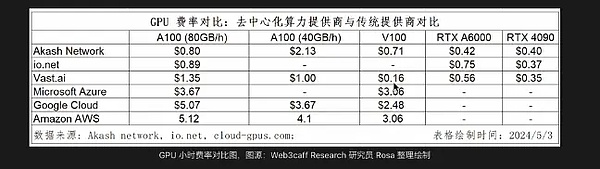
2.4 财务表现
不管token model如何设计,一个健康的tokenomics都需要满足以下几个基本条件:1)用户对于网络的需求需要体现在币价上,也就是说代币是可以实现价值捕获的;2)各个参与者,不管是开发者、节点、用户都需要得到长期的公平的激励;3)保证去中心化的治理,避免内部人士过度持有;4)合理的通胀和通缩机制和代币释放周期,避免大幅波动的币价影响网络的稳健型和持续性。
如果把代币模型笼统地分为BME(burn and mint equilibrium)和SFA(stake for access),这两种模式的代币通缩压力来源不同:BME模型在用户购买服务后会燃烧代币,因此系统的通缩压力是由需求决定的。而SFA要求服务提供者/节点质押代币以获得提供服务的资格,因此通缩压力是由供给带来的。BME的好处在于更加适合用于非标准化商品。但如果网络的需求不足,可能面临着持续通胀的压力。各项目的代币模型在细节上有差异,但总体来说,Aethir更偏向于SFA,而io.net,Render Network和Akash Network更偏向于BME,Gensyn尚未可知。
从收入来看,网络的需求量会直接反映在网络整体收入上(这里不讨论矿工的收入,因为矿工除了完成任务所获的报酬还有来自于项目的补贴。)从公开的数据上来看io.net的数值是最高的。Aethir的收入虽然还未公布,但从公开信息来看,他们宣布已经与很多B端客户签下了订单。
从币价来说,目前只有Render Network和Akash Network进行了ICO。Aethir和io.net也在近期发币,价格表现需要再观察,在这不做过多讨论。Gensyn的计划还不清楚。从发币的两个项目以及同一个赛道但没有包含在本文讨论范围内的已经发币的项目,综合来讲,去中心化算力网络都有非常亮眼的价格表现,一定程度体现了巨大的市场潜力和社区的高期望。
2.5 总结
去中心化算力网络赛道总体发展很快,已经有很多项目可以依靠产品服务客户,并产生一定收入。赛道已经脱离了纯叙事,进入可以提供初步服务的发展阶段。
需求疲软是去中心化算力网络所面临的共性问题,长期的客户需求没有被很好地验证和挖掘。但需求侧并没有过多影响币价,已经发币的几个项目表现亮眼。
AI是去中心化算力网络的主要叙事,但并不是唯一的业务。除了应用于AI training和inference之外,算力还可被用于云游戏实时渲染,云手机服务等等。
算力网络的硬件异质化程度较高,算力网络的质量和规模需要进一步提升。
对于C端用户来说,成本优势不是十分明显。而对于B端用户来说,除了节约成本之外,还需考虑服务的稳定性、可靠性、技术支持、合规和法律支持等等方面,而Web3的项目普遍在这些方面做得不够好。
3 Closing thoughts
AI的爆发式增长带来的对于算力的巨量需求是毋庸置疑的。自 2012 年以来,人工智能训练任务中使用的算力正呈指数级增长,其目前速度为每3.5个月翻一倍(相比之下,摩尔定律是每18个月翻倍)。自2012 年以来,人们对于算力的需求增长了超过300,000倍,远超摩尔定律的12倍增长。据预测,GPU市场预计将在未来五年内以32%的年复合增长率增长至超过2000亿美元。AMD的估计更高,公司预计到2027年GPU芯片市场将达到4000亿美元。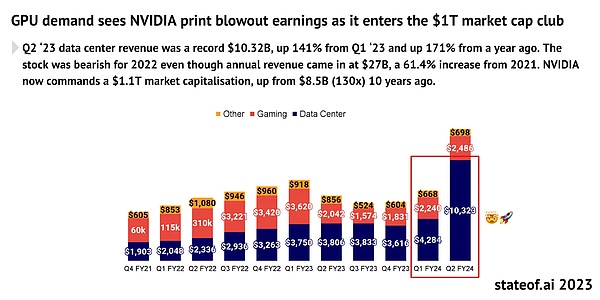
图片来源: https://www.stateof.ai/
因为人工智能和其他计算密集型工作负载(如AR/VR渲染)的爆发性增长暴露了传统云计算和领先计算市场中的结构性低效问题。理论上去中心化算力网络能够通过利用分布式闲置计算资源,提供更灵活、低成本和高效的解决方案,从而满足市场对计算资源的巨大需求。因此,crypto与AI的结合有着巨大的市场潜力,但同时也面临与传统企业激烈的竞争、高进入门槛和复杂的市场环境。总的来说,纵观所有crypto赛道,去中心化算力网络是加密领域中最有希望获得真实需求的的垂直领域之一。
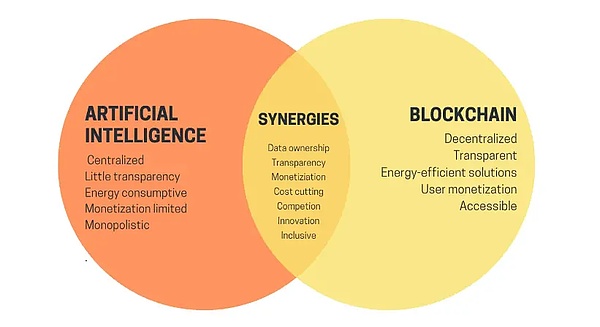
图片来源:https://vitalik.eth.limo/general/2024/01/30/cryptoai.html
前途是光明的,道路是曲折的。想要达到上述的愿景,我们还需要解决众多的问题与挑战,总结来说:现阶段如果单纯提供传统的云服务,项目的profit margin很小。从需求侧来分析,大型企业一般会自建算力,纯C端开发者大多会选择云服务,真正使用去中心化算力网络资源的中小型企业是否会有稳定需求还需要进一步挖掘和验证。另一方面,AI是一个拥有极高上限和想象空间的广阔市场,为了更广阔的市场,未来去中心化算力服务商也需要向模型/AI服务进行转型,探索更多的crypto + AI的使用场景,扩大项目能够创造的价值。但目前来说,想要进一步发展到AI领域还存在很多问题和挑战:
价格优势并不突出:通过之前的数据对比可以看出,去中心化算力网络的成本优势并没有得到体现。可能的原因在于对于需求大的专业芯片H100、A100等,市场机制决定了这部分硬件的价格不会便宜。另外,去中心化网络虽然能收集闲置的算力资源,但去中心化带来的规模经济效应的缺乏、高网络和带宽成本以及极大的管理和运维的复杂性等隐形成本会进一步增加算力成本。
AI training的特殊性:利用去中心化的方式进行AI trainning在现阶段有着巨大的技术瓶颈。这种瓶颈从GPU的工作流程当中可以直观体现,在大语言模型训练中,GPU首先接收预处理后的数据批次,进行前向传播和反向传播计算以生成梯度。接下来,各GPU会聚合梯度并更新模型参数,确保所有GPU同步。这个过程将不断重复,直到训练完成所有批次或达到预定轮数。这个过程中涉及到大量的数据传输和同步。使用什么样的并行和同步策略,如何优化网络带宽和延迟,降低通讯成本等等问题,目前都还未得到很好的解答。现阶段利用去中心化算力网络对AI进行训练还不太现实。
数据安全和隐私:大语言模型的训练过程中,各个涉及数据处理和传输的环节,比如数据分配、模型训练、参数和梯度聚合都有可能影响数据安全和隐私。并且数据隐私币模型隐私更加重要。如果无法解决数据隐私的问题,就无法在需求端真正规模化。
从最现实的角度考虑,一个去中心化算力网络需要同时兼顾当下的需求发掘和未来的市场空间。找准产品定位和目标客群,比如先瞄准非AI或者Web3原生项目,从比较边缘的需求入手,建立起早期的用户基础。同时,不断探索AI与crypto结合的各种场景,探索技术前沿,实现服务的转型升级。
参考文献
https://www.stateof.ai/
https://vitalik.eth.limo/general/2024/01/30/cryptoai.html
https://foresightnews.pro/article/detail/34368
https://app.blockworksresearch.com/unlocked/compute-de-pi-ns-paths-to-adoption-in-an-ai-dominated-market?callback=%2Fresearch%2Fcompute-de-pi-ns-paths-to-adoption-in-an-ai-dominated-market
https://research.web3caff.com/zh/archives/17351?ref=1554
 1
1
声明:本文由入驻金色财经的作者撰写,观点仅代表作者本人,绝不代表金色财经赞同其观点或证实其描述。
提示:投资有风险,入市须谨慎。本资讯不作为投资理财建议。


24小时热文


 a16z:目前到底有多少真实加密用户
a16z:目前到底有多少真实加密用户金色财经


 Meme币 + 功能型代币 = 社区网络
Meme币 + 功能型代币 = 社区网络Block unicorn
 谁在买比特币?2024年ETF与机构投资者全景解析
谁在买比特币?2024年ETF与机构投资者全景解析YoubiCapitai
 都202X年了 这空投还能撸吗?
都202X年了 这空投还能撸吗?Biteye
 DeFi生态有创新异动?
DeFi生态有创新异动?道说区块链
 以太坊未平仓合约峰值 暴跌或将上演
以太坊未平仓合约峰值 暴跌或将上演金色精选

- 寻求报道
- 金色财经APPiOS & Android
- 加入社群
Telegram - 意见反馈
- 返回顶部
- 返回底部